Доверительный интервал
Что такое доверительный интервал:
Это оценка диапазона, используемого в статистике, который содержит параметр совокупности. Этот неизвестный параметр популяции находится в выборочной модели, рассчитанной на основе собранных данных .
Пример: среднее значение выборки x̅ может соответствовать или не соответствовать истинному среднему значению для населения µ. Для этого можно рассмотреть диапазон выборочных средств, в которых может содержаться это среднее значение. Чем длиннее этот интервал, тем больше вероятность этого.
Доверительный интервал выражается в процентах, обозначенных уровнем достоверности, причем 90%, 95% и 99% являются наиболее указанными. Например, на изображении ниже мы имеем 90% доверительный интервал между его верхним и нижним пределами (a и -a ).
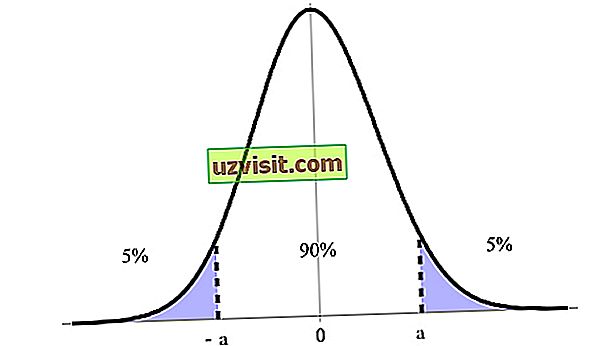
Доверительный интервал является одним из наиболее важных понятий в рамках проверки гипотез в статистике, поскольку он используется в качестве меры неопределенности. Термин был введен польским математиком и статистиком Ежи Нейманом в 1937 году.
Какова актуальность доверительного интервала?
Доверительный интервал важен для указания границы неопределенности (или неточности) в сравнении с выполненными расчетами. Этот расчет использует выборку исследования для оценки фактического размера результата в исходной популяции.
Расчет доверительного интервала - это стратегия, которая учитывает выборку ошибок. Размер результата вашего исследования и ваш доверительный интервал характеризуют предполагаемые значения для исходной популяции.
Чем уже доверительный интервал, тем больше вероятность того, что процент исследуемой совокупности представляет реальное число исходной совокупности, что дает большую уверенность в отношении результата исследуемого объекта.
Как интерпретировать доверительный интервал?
Правильная интерпретация доверительного интервала, вероятно, является наиболее сложным аспектом этой статистической концепции. Примером наиболее распространенной интерпретации концепции является следующее:
Существует 95% вероятность того, что в будущем истинное значение параметра совокупности (например, среднее значение) попадет в диапазон X (нижний предел) и Y (верхний предел).
Таким образом, доверительный интервал интерпретируется следующим образом: он на 95% уверен, что интервал между X (нижняя граница) и Y (верхняя граница) содержит истинное значение параметра совокупности.
Было бы совершенно неверно утверждать, что: существует 95% вероятность того, что интервал между X (нижняя граница) и Y (верхняя граница) содержит реальное значение параметра совокупности.
Вышеприведенное утверждение является наиболее распространенным заблуждением о доверительном интервале. После расчета статистического диапазона он может содержать только параметр совокупности или нет.
Тем не менее, интервалы могут варьироваться между выборками, в то время как истинный параметр популяции одинаков независимо от выборки.
Следовательно, доверительный интервал доверительного интервала может быть сделан только в случае, когда доверительные интервалы пересчитываются для количества выборок.
Этапы расчета доверительного интервала
Диапазон рассчитывается с использованием следующих шагов:
- Соберите пример данных: n ;
- Рассчитать среднее значение выборки x̅;
- Определить, является ли стандартное отклонение популяции ( σ ) известным или неизвестным;
- Если стандартное отклонение популяции известно, z- точка может использоваться для соответствующего уровня достоверности;
- Если стандартное отклонение популяции неизвестно, мы можем использовать статистику t для соответствующего уровня достоверности;
- Таким образом, нижний и верхний пределы доверительного интервала находятся по следующим формулам:
а) Стандартное отклонение известной популяции :
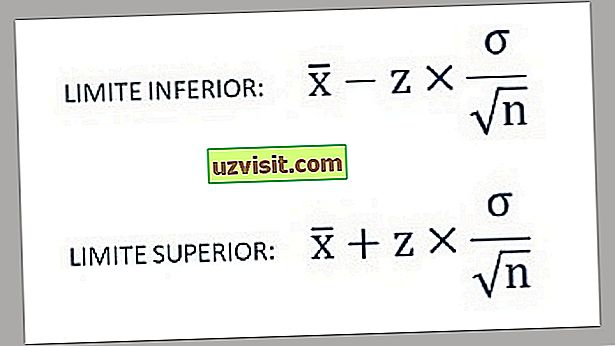
Формула для расчета стандартного отклонения известной совокупности.
б) стандартное отклонение неизвестной популяции :

Формула для расчета стандартного отклонения неизвестной популяции.
Практический пример доверительного интервала
Клиническое исследование оценило связь между наличием астмы и риском развития обструктивного апноэ сна у взрослых.
Некоторые взрослые были случайным образом набраны из списка государственных служащих, за которыми следили в течение четырех лет.
Участники с астмой, по сравнению с теми, у кого нет, имели более высокий риск развития апноэ через четыре года.
При проведении клинических исследований, подобных этому примеру, подмножество интересующей группы населения обычно привлекается для повышения эффективности исследования (меньше затрат и меньше времени).
Эта подгруппа лиц, изучаемая популяция, состоит из тех, кто соответствует критериям включения и согласен участвовать в исследовании, как показано на рисунке ниже.

Затем исследование завершается и рассчитывается величина эффекта (например, средняя разница или относительный риск ), чтобы ответить на вопрос исследования.
Этот процесс, называемый выводом, включает использование данных, собранных у исследуемой совокупности, для оценки величины фактического воздействия на представляющую интерес совокупность, то есть совокупность происхождения.
В приведенном примере исследователи набрали случайную выборку государственных служащих (исходная популяция), которые имели право и согласились участвовать в исследовании (исследуемая популяция), и сообщили, что астма увеличивает риск развития апноэ в исследуемой популяции.
Чтобы учесть ошибку выборки из-за набора только подгруппы представляющего интерес населения, они также рассчитали 95% доверительный интервал (около оценки) от 1, 06 до 1, 82, что указывает на вероятность 95 %, что истинный относительный риск в исходной популяции будет между 1, 06 и 1, 82 .
Доверительный интервал для среднего
Когда у человека есть информация о стандартном отклонении населения, он может рассчитать доверительный интервал для среднего или среднего значения этого населения.
Когда измеряемая статистическая характеристика (например, доход, IQ, цена, рост, количество или вес) является числовой, в большинстве случаев оценивается, что найдено среднее значение для населения.
Таким образом, мы пытаемся найти среднее значение популяции ( μ ), используя среднее значение выборки ( x̅ ), с пределом погрешности. Результат этого расчета называется доверительным интервалом для среднего населения .
Когда стандартное отклонение популяции известно, формула для доверительного интервала (CI) для среднего значения популяции:

где:
- х̅ - среднее значение по выборке;
- σ - стандартное отклонение населения;
- n - размер выборки;
- Ζ * представляет подходящее значение стандартного нормального распределения для желаемого уровня достоверности.
Ниже приведены значения для различных уровней достоверности ( Ζ * ):
| Уровень доверия | Значение Z * - |
|---|---|
| 80% | 1:28 |
| 90% | 1.645 (обычный) |
| 95% | 1, 96 |
| 98% | 2:33 |
| 99% | 2:58 |
В таблице выше приведены значения z * для предоставленных уровней достоверности. Обратите внимание, что эти значения получены из стандартного нормального распределения (Z-).
Область между каждым значением z * и отрицательным значением этого значения является (приблизительным) процентом достоверности. Например, область между z * = 1, 28 и z = -1, 28 составляет приблизительно 0, 80. Следовательно, эта таблица также может быть расширена до других доверительных процентов. В таблице указаны только наиболее часто используемые проценты доверия.
Смотрите также значение гипотезы.


